|
I am a final-year Computer Science PhD candidate at Koç University, advised by Deniz Yuret, and an AI Research Fellow at the KUIS AI Center in Istanbul. I expect to defend my thesis in 2026. My research focuses on memory augmentation for language models — adding external memory to transformers so they can model long contexts efficiently. Email / CV / Semantic Scholar / Google Scholar / Twitter / Github |

|
|
I am interested in natural language processing, language modeling (both large and small models),
and deep learning in general. My PhD research is primarily focused on separating semantic and
episodic information in language models, as well as developing improved memory architectures
for modeling long sequences with Transformers.
|
|
|
|
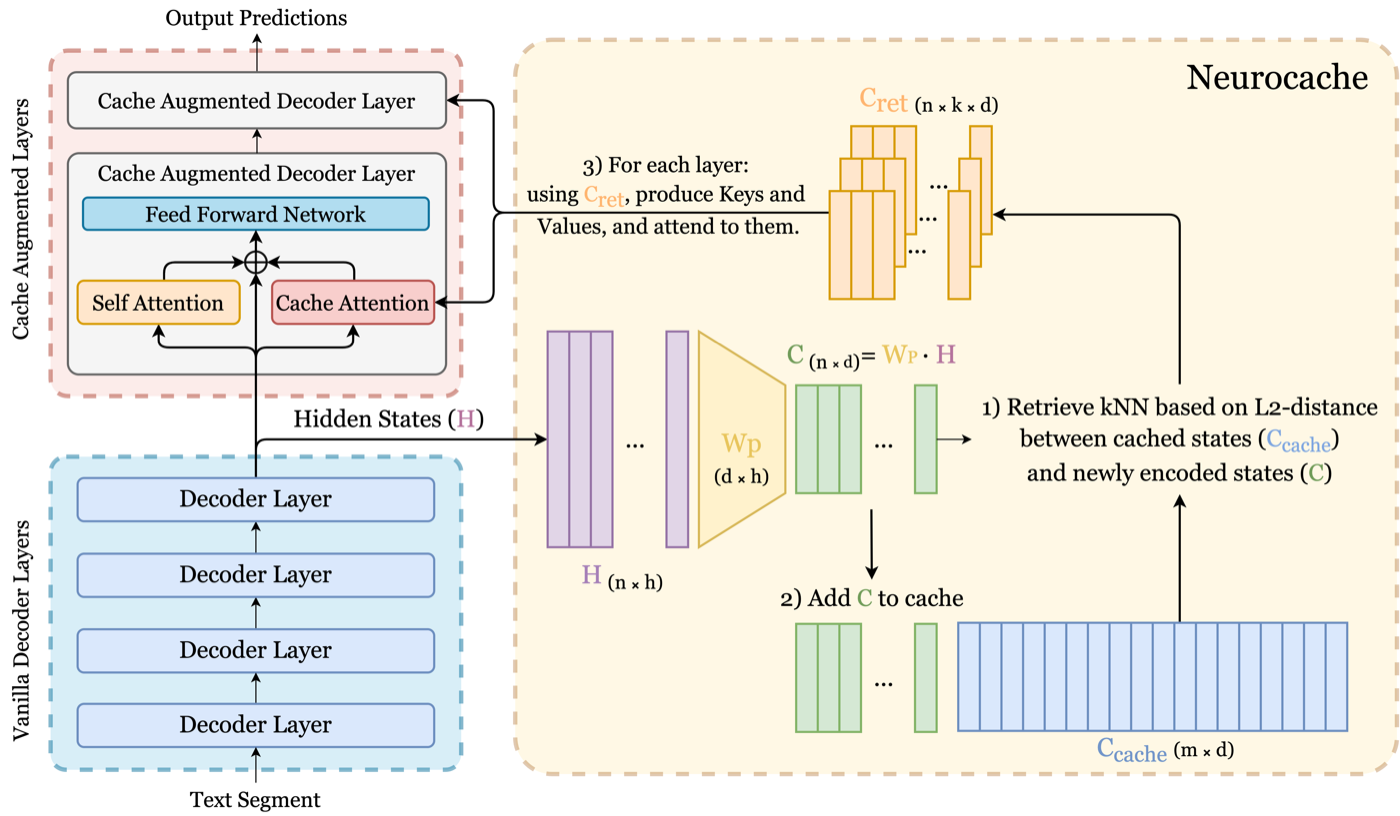
Ali Safaya, Deniz Yuret NAACL 2024 ACL Anthology / arXiv / Code Neurocache extends the effective context of large language models with an external vector cache of compressed past states, retrieved through efficient k-nearest-neighbor lookup and fused back into the attention layers. |

|
Ali Safaya · Turkish Data Depository 2B-parameter Turkish LLM · Hugging Face Model card Kanarya is a 2-billion-parameter Turkish language model based on the GPT-J architecture, pretrained on large-scale filtered Turkish web text and released openly for Turkish text generation and NLP research. |

|
Ali Safaya, Emirhan Kurtulus, Arda Goktogan, Deniz Yuret Findings of ACL 2022 Project page / Video / ArXiv Mukayese is a collection of NLP benchmarks for the Turkish language, consisting of seven leaderboards for different NLP tasks. For each benchmark, we work with one or more datasets and present two or more baselines. |
|
|
|
|
|
This website is based on Jon Barron website's source code. |