|
Email / Semantic Scholar / Google Scholar / Twitter / Github |
Understanding the Impact of Token Redundancy in Language Models31 May 2023TL;DRSubword tokenizers such as SentencePiece and Byte-Pair Encoding (BPE)
represent the same word with different tokens depending on whether it is prefixed
by a space (e.g. IntroductionTo see where this comes from, let's look at how a subword tokenizer handles words and subwords, using the GPT2Tokenizer as an example. The GPT2Tokenizer is a byte-level BPE tokenizer commonly used in pre-trained language models like GPT-2, GPT-3, RoBERTa, and BART. BPE learns a vocabulary by progressively merging the most frequently occurring character or token pairs, gradually building a subword vocabulary that can handle Out-of-Vocabulary (OOV) and rare terms. The GPT2Tokenizer uses byte-level BPE, which operates on raw bytes. Importantly, before merging it applies a regex-based pre-tokenization that splits text on whitespace and keeps each leading space attached to the token that follows it — and that step is exactly what produces the space-prefixed token forms we discuss below. Both BPE and SentencePiece models reserve tokens to represent the space
character. However, it's worth noting that the space character is also
encoded in nearly 50% of the tokens. When a token is prefixed with a space, it
signifies that the token represents a complete word rather than a subword.
Typically, a special character is used to represent the prefixed space. For
instance, GPT2Tokenizer uses Let's illustrate this with an example using the GPT2Tokenizer: In this case, Take a look at the following examples: Here, we can observe that the same sentence is tokenized differently based solely on the presence or absence of a leading space. When the vocabulary is built, a word that appears with no preceding space (for example at the start of the text) is seen as a bare token, while the same word occurring after a space is seen as a space-prefixed token. Because both patterns are common in the training corpus, both forms end up in the vocabulary. Upon analyzing the GPT2Tokenizer, we can identify a category of approximately 8,535 words that exhibit this behavior. Here are a few examples: In total, around 8,535 words appear in both forms — roughly 17% of the GPT2Tokenizer's 50,257-token vocabulary. At first glance these look like unnecessary duplicates, though, as we will see, the two forms are not quite interchangeable. So, what does this mean in practice?Consider the following tokenization examples using both the GPT2Tokenizer and BLOOM tokenizer:
In the GPT2Tokenizer output, the first occurrence of It is tempting to treat this as pure waste, but the two forms are not interchangeable: the leading space records whether a word follows whitespace, and the tokenizer relies on that to reconstruct the original text exactly when decoding. So this is less "redundancy to be removed" and more a boundary distinction that the model has to learn to handle. The genuinely practical concern — which we return to at the end — is making sure the same text is always tokenized the same way. How do the models treat this phenomenon?Models seem to learn to handle these two forms in a similar way. To illustrate this, let's examine the cosine similarity between the embedding vectors of such token pairs. 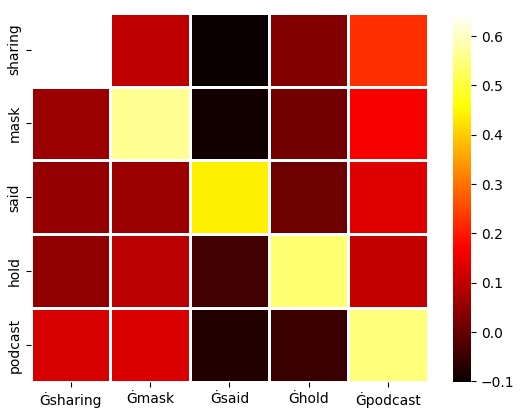
Heatmaps of cosine similarity between GPT2Tokenizer embeddings for 5 and 1,000 words (respectively). Rows are the bare tokens and columns their space-prefixed counterparts, aligned so that cell (i, i) compares the two forms of the same word. The words are chosen at random; the bright diagonal shows that a word's two forms are far more similar to each other (about 0.5–0.6) than to other tokens (near 0). The heatmaps show that the two forms of a word end up with closely related embeddings, even though they remain distinct tokens. This makes sense: trained on large corpora, the model sees both forms in similar contexts and learns representations that reflect their shared meaning while still encoding the boundary difference. In principle this similarity could be exploited to shrink the vocabulary or merge these embeddings together, but that is beyond the scope of this article. What is the solution?The practical fix is to tokenize text consistently. The simplest step is to add a
prefix space before tokenizing, so that the first word of a string takes the same
space-prefixed form it would have mid-sentence. Most tokenizers support this
through the However, this solution doesn't completely resolve the problem for multiline tokenizers. Let's consider the example of the LLaMA tokenizer: Here, we can see that the LLaMA tokenizer applies the
To handle this in multiline tokenizers, an additional normalization step can be
applied. Along with ConclusionSubword tokenizers represent a word with more than one token depending on a leading space, and in the GPT2Tokenizer roughly 17% of the vocabulary takes this paired form. These forms look redundant, but the leading space encodes word-boundary information, and models readily learn closely related embeddings for the two variants, as the cosine-similarity heatmaps show. The practical takeaway is therefore less about eliminating "redundant" tokens and more about consistency: applying a prefix space (and, for multiline text, normalizing line breaks) so that the same text is always tokenized the same way, matching how the model was trained. Handled consistently, these multiple token forms are a non-issue rather than a hidden inefficiency. |